Motivation
It is widely recognized that a major disruption is under way in computer hardware as processors strive to extend, and go beyond, the end of Moore’s Law. This disruption is bringing the emergence of new heterogenous processors and memories, near-memory computation structures, and even Non-von Neumann computing elements.
Unlike previous generations of hardware evolution, these “extreme heterogeneity” platforms will have a profound impact on future software. The software challenges are further compounded by the need to support new workloads and application domains (e.g., data analytics, machine learning), that traditionally received less attention in high performance computing.
Further, since the end of Dennard Scaling 20+ years ago, all performance-sensitive software needs to be parallel and distributed by default, given the increasing presence of distributed memories in heterogeneous processors and clusters. However, the current foundations of parallel and distributed software are unstructured and non-compositional in nature, as exemplified by the use of threads, locks, barriers, and blocking communications as underlying primitives, and limit the ability of modern applications to use the capabilities of current and future processor hardware.
Mission
The Habanero Extreme Scale Software Research Laboratory was founded to address the challenges of creating software for extreme scale parallel systems (1000+ way parallelism per socket, 1M+ way parallelism per rack, 1B+ way parallelism per cluster).
We strive to enable future software to be developed with programming systems that enable application developers to reuse their investments across multiple generations of extreme scale hardware platforms, and to harness the capabilities of these platforms as productively as possible. Our research towards this goal is driven by a new foundation for parallel and distributed software based on structured and compositional execution model primitives that enable enhanced performance and verifiability relative to past models.
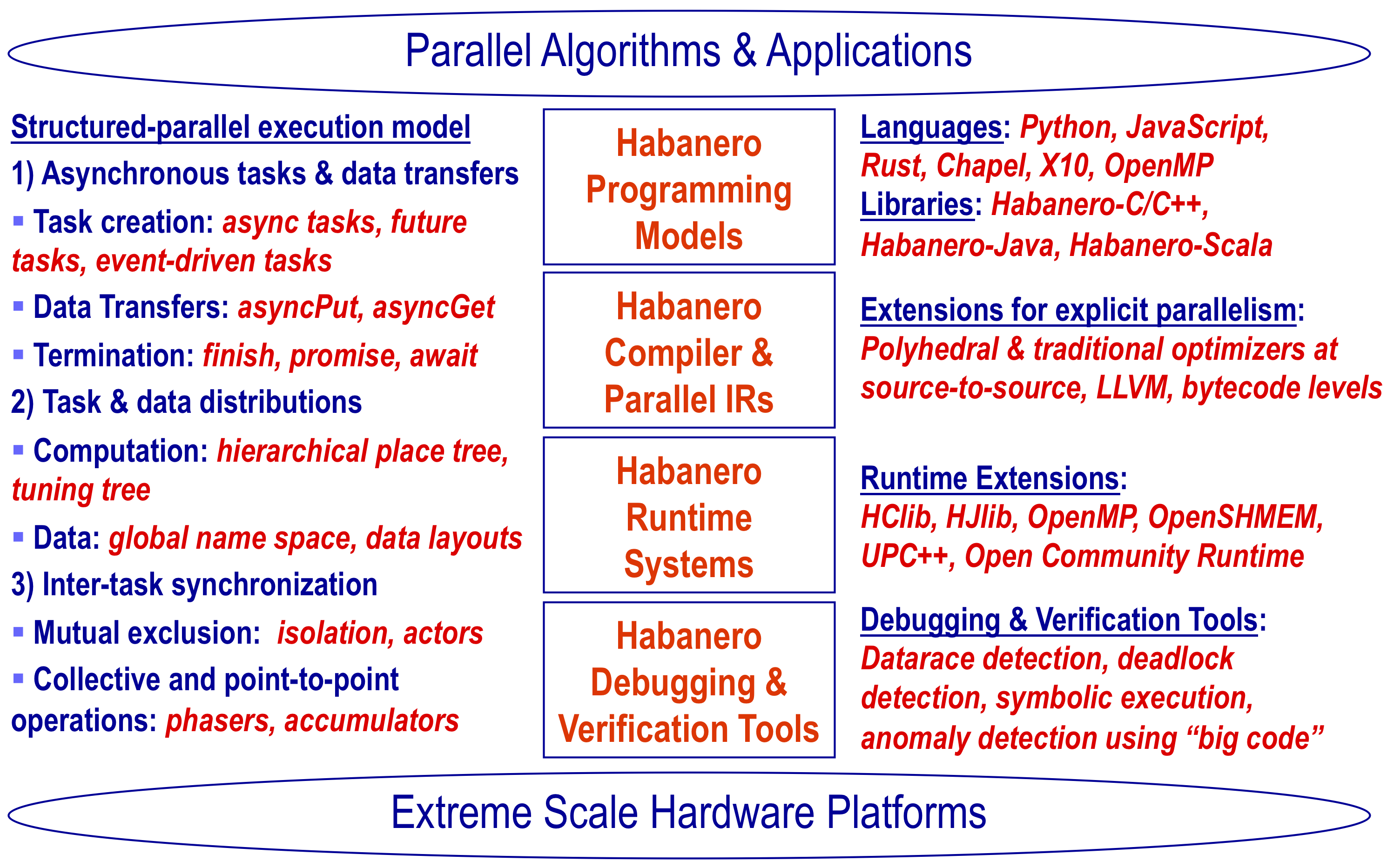
We do this through a combination of research on:
- Programming Models
- Compilers
- Runtime Systems
- Debugging & Verification tools
Impact
In addition to providing tools and resources for the HPC community, we also envision the broader impact of this research, including:
- Updating the pedagogy of parallel computing in introductory Computer Science courses
- Building open-source testbeds to grow the ecosystem of researchers in the parallel software area
- Adapting our research infrastructure towards building reference implementations for future industry standards.